| 要約: | - 正規表現を使用して、文字列が特定のパターンに一致するかどうかを判別できます。
- これらの表現は、特定のパターンに一致する必要があるユーザー入力やデータ ファイルの解析に役に立ちます。
- Curl® 言語は Perl プログラミング言語の高レベルの正規表現構文を採用し、多くの異なる種類のデータ抽出やレポート作成タスクに適しています。
|
正規表現を使用して、文字列が特定のパターンに一致するかどうかを判別できます。正規表現の構文を使用して、文字列と比較するパターンを定義します。
正規表現は、特定のパターンに一致する必要があるユーザー入力やデータ ファイルの解析に役に立ちます。たとえば、有効な社会保障番号と電話番号であれば、いずれも特定のパターンに一致します。正規表現により、番号が適切な形式かどうかを確認したり、データの抽出や操作を簡単に行なうことができます。正規表現の構文は柔軟性があり、1 つの表現で複数の異なる有効なパターンの意味を定義できます。たとえば 1 つの正規表現だけで、各国で使用されている電話番号の形式を米国 ((nnn) nnn-nnnn)、英国 (nnnn nnn nnn)、およびフランス (nn.nn.nn.nn.nn) のように識別することができます。
Curl 言語の高レベルの正規表現構文は、Perl プログラミング言語から採用されています。したがって、Curl 言語は多くの異なるの種類のデータ抽出やレポート作成タスクに適しています。
正規表現の作成に使用される構文は Curl 言語のネイティブ構文とは異なり、かなり複雑になる場合があります。以下のセクションでは、正規表現の基本的な概念を説明し、インタラクティブな例を示します。これらの例では、上に正規表現を表示し、下に正規表現を複数の文字列と比較した結果を表示します。正規表現とそれにマッチさせる文字列を編集して、正規表現を使って試してみてください。フィールドの 1 つを編集すると表示される Update ボタンをクリックして、結果を更新します。正規表現または文字列を変更した後で元の例に戻するには、Restore をクリックします。
最も簡単な正規表現は、英数字を 1 文字だけ含むものです。その文字を含む文字列とマッチします。単一文字の正規表現では、大文字と小文字が区別されます。
正規表現の構文で使用される多数の特殊文字があります。これらの文字をその特殊な意味としてではなく正規表現として使用する場合、バックスラッシュ文字 (\) を使用してエスケープする必要があります。エスケープが必要な文字には、\、|、{、}、+、*、(, )、.、^、$、 ? があります。
アプレットで正規表現を指定する場合、正規表現の特殊文字の一部は Curl 言語の予約文字でもある点に留意してください。
「
予約文字」を参照してください。次の例では、ドット文字 (.) に一致する正規表現を作成するためにバックスラッシュをエスケープしなければならない点に注目してください。
| 例:
アプレットでの正規表現 |
 |
{import * from CURL.LANGUAGE.REGEXP}
{let s:String = "abc ... def"}
{let exp:String = "\\."}
{set s = {regexp-subst
exp,
s,
"",
replace-all? = true}}
{value s}
| |
次の例では、逐語的文字列を使って文字列と正規表現に予約文字を含めています。
「
逐語的文字列」を参照してください。
| 例:
逐語的文字列と正規表現 |
 |
{import * from CURL.LANGUAGE.REGEXP}
{let s:String = |"abc ||| def"|}
{let exp:String = |"\|"|}
{set s = {regexp-subst
exp,
s,
"",
replace-all? = true}}
{value s}
| |
ワイルドカードにより、数字や文字など特定のカテゴリに分類される単一文字とマッチできます。単一文字の正規表現と同様に、ワイルドカード文字は 1 文字だけとマッチします。
ワイルドカードの要約を次の表に示します。
| 構文 | 意味 |
|---|
| . | 改行文字以外の任意の文字とマッチします。 |
| \d | 任意の数字とマッチします。 |
| \D | 数字以外の任意の文字とマッチします。 |
| \s | 任意の空白文字とマッチします。 |
| \S | 空白以外の任意の文字とマッチします。 |
| \w | 単語を構成する任意の文字とマッチします。 |
| \W | 単語を構成する文字以外の任意の文字とマッチします。 |
注意: 数字
、
空白
、および
単語を構成する文字
の内容は、現在の
Locale の設定によって決まります。
ワイルドカードとマッチ可能な事前定義の一連の文字に加えて、マッチさせる文字のリストを指定することもできます。
マッチさせる文字を明示的に選択するには、それらを角カッコ ([]) で囲みます。リスト内の文字のみがマッチします。これらのマッチングでは大文字と小文字が区別されます。
注意: ハイフン (-)、キャレット (^)、終了角カッコ (]) およびバック スラッシュ(\) 文字は、角カッコ内では特別に扱います。
ハイフンは、開始角カッコの後にくる一番最初の文字でなければなりません。キャレットは一番最初の文字に使用できません。
バック スラッシュおよび終了角カッコ 文字はバック スラッシュでエスケープする必要があります。
開始角カッコの後に始めて出てくる文字が終了角カッコの場合はエスケープする必要はありません。(例えば、[][] は [\][] と同等であり、開始/終了カッコとマッチします。)
その他の文字は、角カッコ内でエスケープする必要はありません。
各文字の明示的なリストの代わりに文字の範囲を指定する場合もあります。この場合、ハイフン (-) を使用してマッチする文字の範囲を指定できます。たとえば、[a-z] は、すべての小文字とマッチします。ワイルドカードにハイフンを含めるには、それをリストの最初の文字として含めます。
範囲は Unicode 値に基づいています。たとえば、文字 0
は Unicode 値 \u0030、a
は \u0061 です。[0-a] の範囲には、すべての数字 0-9、句読点の一部およびすべての大文字 A-Z と小文字 a が含まれます。
キャレット (
^) を角カッコ内の最初の文字として含めると、リストを反転できます。否定文字のリストは、リストに
含まれていない任意の文字とマッチします。
単一の文字とマッチできてもあまり役には立ちません。複数の文字とマッチする正規表現は、複数の演算子を使用して、単一文字の正規表現から作成します。
複数文字の文字列とのマッチングでは、単一文字の正規表現を連結して使用します。単一文字の正規表現のそれぞれに一致するものが文字列にあれば、その文字列はマッチします。
パターンを 1 度またはそれ以上含む文字列とのマッチングが必要な場合があります。この場合、繰り返し演算子を正規表現の直後に指定して、正規表現を繰り返してマッチングさせたり、あるいはマッチングさせないようにすることができます。
| 構文 | 意味 |
|---|
| regexp* | regexp (正規表現) を 0 回以上連続して含む部分文字列とマッチします。 |
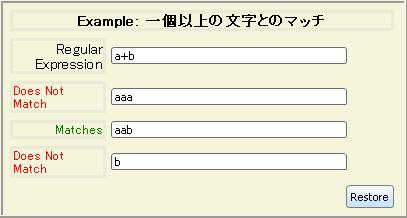
| regexp+ | regexp を 1 回以上連続して含む部分文字列とマッチします。 |
| regexp? | regexp を含まない、あるいは 1 回含む部分文字列とマッチします。 |
| regexp{m,n} | regexp を m 回以上、n 回以下連続して含む部分文字列とマッチします。 |
| regexp{m,} | regexp を m 回以上連続して含む部分文字列とマッチします。 |
| regexp{n} | regexp を n 回連続して含む部分文字列とマッチします。 |
選択演算子
| は、Curl 言語の式における
or 演算子と似たような機能で、いずれか一方の正規表現とマッチすることができます。
| 構文 | 意味 |
|---|
| regexp1 | regexp2 | regexp1 または regexp2 のいずれかを含む文字列とマッチします。 |
通常の Curl 言語の式と同じように、正規表現演算子にもあいまいさを避けるための優先順位があります。
優先順位の高いものから低いものの順に並べた正規表現演算子は以下のとおりです。
正規表現を作成するときは、これらのルールを考慮する必要があります。たとえば、繰り返しは連結よりも優先順位が高いので、文字列の最後に + を追加するだけでは、結果として得られる正規表現が元の文字列全体の 1 度以上の繰り返しとマッチすることにはなりません。つまり、+ 演算子は文字列の最後の文字が残り部分と連結される前に評価されるため、文字列の最後の文字だけに適用されています。
同様に、連結は選択よりも優先順位が高いので、文字列は選択演算子が適用される前に連結されます。これは、文字列内の 2 つの文字のどちらかを選択するのに選択演算子を使用できないことを意味します。
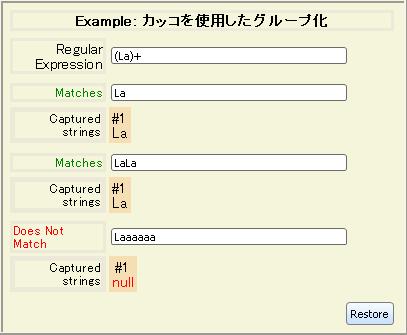
Curl 言語の式と同様に、カッコを使用して正規表現内の優先順位を制御し、低い優先順位の演算子をグループ化することができます。たとえば、文字列をカッコで囲んで、+ または * などの任意の演算子が適用される前に、文字列全体が確実に連結されるようにします。
上記の例では、
マッチ
だけでなく
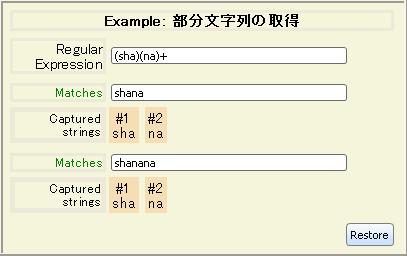
キャプチャされた文字列
も表示されています。キャプチャされた文字列とは、カッコで囲まれた正規表現部分に一致する部分文字列です。キャプチャされた部分文字列を取得したり、表現内で再利用することができます。修飾子フラグを使用する表現は部分文字列をキャプチャしません。「
修飾子のある部分文字列の取得」の例を参照してください。
取得された部分文字列には、左端のカッコを 1 として順に番号が付けられます。マッチがないカッコは、取得した部分文字列として
null を返します。ただし、それにも番号が付けられています。カッコがネストされている場合は、中のカッコより先に外側のカッコに番号が付けられます。
カッコの内容が別の文字列とマッチできる場合、およびカッコの正規表現が文字列で複数回マッチする場合は、カッコで取得された部分文字列として、マッチした最後の部分文字列が返されます。
取得された文字列で何ができるでしょうか。たとえば、取得した文字列を参照し、マッチしている文字列内で別の場所に移動するというようなことが可能です。この場合、バックスラッシュ (\) の後に取得された文字列の番号を続け、取得した文字列を参照します。
後方参照(backward reference)では、カッコ内の表現で取得された最後の文字列のみを使用できます。
開きカッコの後ろに ?P<name> を挿入して、文字列のキャプチャ表現に名前を付けることができます。この場合、name は任意の有効な Curl 識別子を指します。たとえば、次の例では ISO フォーマットの日付文字列に一致する表現の可変部分に名前を与えています。
| 例:
Accessing named substring through a MatchState |
 |
{import * from CURL.LANGUAGE.REGEXP}
{value
let matcher:Matcher = {Matcher |"<(?P.*)>"|}
{if-non-null state = {matcher.match ""} then
state["name"]
else
"NO-MATCH"
}
}
| |
同じ正規表現内で前にある名前付き部分文字列を参照する場合、構文 (?P=name) を使います。たとえば、次の例では Curl のタグ コメントに一致する表現を示しています。ここで、(?P=tag) は \1 と書くのと同じです。
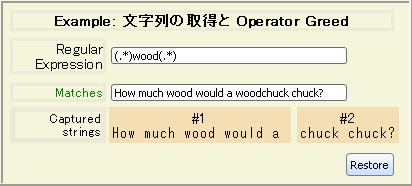
* などの乗算演算子は、正規表現が複数回マッチすることが許される greedy (欲張り)
な演算子です。正規表現の他の部分が文字列の文字の一部とマッチする場合でも、これらの演算子はできるだけ多くの部分の文字列とのマッチングを行ないます。つまり、この演算子により予想以上に文字列の大半が消費される可能性があり、文字列の取得に影響を及ぼすことになります。
疑問符 (?) を追加して、non-greedy (欲張りではない)
繰り返し可能な演算子にすることができます。
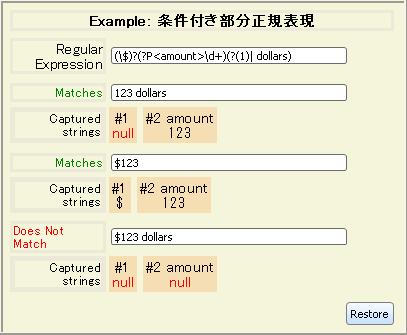
部分正規表現を先にキャプチャした部分文字列マッチングが成功しているかを条件に定義することができる。
| 構文 | 意味 |
|---|
| (?(n)yes|no)) | キャプチャされたn番目の部分正規表現がマッチした場合、正規表現yesとマッチする、そうじゃない場合noとマッチする。 |
| (?(n)yes) | これは次の構文と同一です:
(?(n)yes|)) |
注意: nは普通の後方参照とは異なり、先頭にバックスラッシュがない整数型でなければならない。名前でキャプチャした部分正規表現を参照することはサポートしていない。
次の正規表現式はドル額をパースして、接頭辞“$“がない場合、サフィックス“dollars“のみ検索する例です。
文字とマッチする正規表現のほかに、文字列内の任意の位置とマッチする正規表現の種類があります。これらは実際には文字とマッチしないので、Zero-widthの正規表現と呼ばれます。これらを使用して、正規表現の一部に アンカー
を付け、行頭や行末のような文字列内で指定された位置に配置することができます。
使用可能な組み込みのゼロ幅表現のいくつかを次に示します。
| 構文 | 意味 |
|---|
| ^ | 行頭の直前の空白とマッチします。 |
| $ | 行末の直後、または文字列の末尾の改行の直前の空白とマッチします。 |
| \A | 文字列の先頭の直前とマッチします。 |
| \Z | 文字列の末尾の直後、または文字列の末尾の改行の直前とマッチします。 |
| \z | 文字列の末尾の直後とマッチします。 |
| \b | 単語の境界、つまり単語を構成する任意の文字とそれ以外の文字の間の空白とマッチします (文字列の先頭と末尾の範囲外にある存在しない文字は、単語を構成しない文字として扱われます)。 |
| \B | \b とマッチしない任意の空白とマッチします。 |
行の先頭および末尾と、文字列の先頭および末尾の違いに注意する必要があります。文字列に改行文字が含まれている場合は、文字列内に複数の行があります。したがって、行頭と行末が複数あります。文字列の先頭と末尾は 1 つずつしかありません。
上記のほかに、カスタムの Zero-width 表現を作成することもできます。
| 構文 | 意味 |
|---|
| (?=regexp) | Zero-width の肯定的な表現です。regexp とマッチする任意の部分文字列の直前の空白とマッチします。 |
| (?!regexp) | Zero-width の否定的な表現です。regexp とマッチしない任意の部分文字列の直前の空白とマッチします。 |
| (?<=regexp) | Zero-width の肯定的な表現です。regexp とマッチする任意の部分文字列の直後の空白とマッチします。 |
| (?<!regexp) | Zero-width の否定的な表現です。regexp とマッチしない任意の部分文字列の直後の空白とマッチします。 |
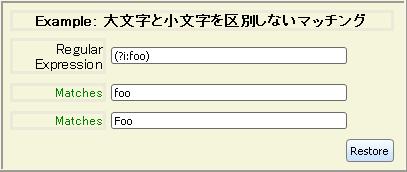
任意の正規表現に適用される 修飾子フラグ
が 3 つあります。
| 修飾子フラグ | 意味 |
|---|
| i | マッチングで大文字と小文字を区別しません。 |
| m | 文字列を複数行として扱います。つまり、^ および $ を使用して、文字列の先頭と末尾だけではなく、文字列に含まれる任意の改行の前後とマッチします。 |
| s | 文字列を "単一行" として扱います。つまり、"." が改行文字を含む任意の文字とマッチするようになります。 |
これらの修飾子はすべて、既定では無効になっています。
これらの修飾子を 1 つ以上適用するには、一般化されたグループ コンストラクトを使用します。
| 構文 | 意味 |
|---|
| (?mods-antimods:regexp) | regexp に対して、mods を適用し、antimods を削除します。mods、antimods、およびそれらの間のマイナス記号は、すべてオプションであることに注意してください。 |
複数の修飾子が regexp に適用される (または regexp から削除される) ときは、最も内側の修飾子が優先されます。
上述の例に見られるように、修飾子を使用する表現は部分文字列をキャプチャしません。
この動作により、部分文字列のキャプチャが必要とする余分な計算上のコストを回避しています。
パフォーマンスを要求されていて、グループ表現の部分文字列をキャプチャする必要がない場合は、
(regexp) の代わりに
(?:regexp) の形式の表現を使用します。
修飾子を持つ表現から部分文字列をキャプチャする場合は追加のカッコが必要になります。
正規表現の作成方法の説明が済んだので、次は Curl 言語で使用してみましょう。
正規表現を Curl 言語で使用する前に、
import を使用して正規表現パッケージをインポートする必要があります。
{import * from CURL.LANGUAGE.REGEXP}
パッケージのインポートの詳細は、「
パッケージ」セクションを参照してください。
Curl 言語では、正規表現はプロシージャおよびオブジェクトに渡される文字列内に格納されます。これらは言語で使用されている特殊文字を含むため、Curl® 実行環境 による解釈の誤りを避けるために、場合によっては作成した正規表現をエスケープする必要があります。文字列内の正規表現であっても、\、{、および } は解釈されます。
注意: 実行環境に解釈されないように正規表現をエスケープすることは、正規表現で特殊文字が解釈されないようにエスケープすることとは異なります。
実行環境 が誤って解釈しないようにするには、正規表現を逐語的テキストにするのが最も簡単な方法です。逐語的テキスト文字列を作成する最も簡単な方法は、正規表現を通常の引用符ではなく |" と "| で囲むことです。「
逐語的文字列」の使用方法については、基本構文のセクションを参照してください。
バックスラッシュ文字 (\) を使用して特殊文字をエスケープする一般的な方法も使用できますが、コードが煩雑になります。これは、バックスラッシュ文字を正規表現で認識される文字として含める場合に特にあてはまります。バックスラッシュを 4 つ (\\\\) 入力しなければならないからです。逐語的文字列を使用すると、正規表現が判読しやすくなります。
| 例:
文字列のマッチング |
 |
{import * from CURL.LANGUAGE.REGEXP}
{regexp-match? "foo", "Hello foobar goodbye"} | |
regexp-match? プロシージャを使用して、正規表現によって取得された任意の部分文字列を抽出し、それを変数に与えて格納することもできます。
| 例:
部分文字列の抽出 |
 |
{import * from CURL.LANGUAGE.REGEXP}
{value
let beg:#String, mid:#String, end:#String
|| Match "foo" within a string. Capture the
|| result in three strings. No need to use verbatim
|| strings here, since the regexp doesn't contain characters
|| that have special meaning in the Curl language.
{if {regexp-match? "^(.*)(foo)(.*)$", "Hello foobar goodbye",
beg, mid, end} then
{HBox {HBox border-width=1pt, border-color="red", beg},
{HBox border-width=1pt, border-color="green", mid},
{HBox border-width=1pt, border-color="blue", end}}
else
"No match"}} | |
次の例は、電話番号が有効である ((nnn) nnn-nnnn または同様の形式) ことを検証し、同時に番号の各部分を抽出する方法を示しています。
| 例:
電話番号のマッチング |
 |
{import * from CURL.LANGUAGE.REGEXP}
{value
let ac:#String, ex:#String, pn:#String
let stat:Graphic = {Fill}
let phone-field:TextField =
{TextField width=2in,
{on ValueChanged do
|| See if the current contents are in an
|| acceptable format, and if so, show
|| the components of the phone number
{if {regexp-match? |"^\(?(\d{3})\)?[\s.]*(\d{3})[\s.\-]*(\d{4})\s*$"|,
phone-field.value, ac, ex, pn} then
|| The phone number is in the proper format, so show it in
|| the result area.
set stat = {stat.replace-with {HBox {text color="green", Valid },
{text Area Code: {value ac},
Exchange: {value ex},
Phone Number: {value pn}}}}
|| The current phone number is not valid, so show that
|| it is currently invalid.
else set stat = {stat.replace-with {text color="red", Invalid}}}}}
{VBox {HBox valign="origin",
{text Phone number:}, phone-field},
{HBox stat}}
}
| |
上の例の正規表現を次に示します。
^\(?(\d{3})\)?[\s.]*(\d{3})[\s.\-]*(\d{4})\s*$
次の表はこの正規表現の各セクションの説明です。
| 表現 | 説明 |
|---|
| ^ | 文字列の先頭とマッチします。 |
| \(? | 0 個または 1 個の左カッコです。 |
| (\d{3}) | 0 個または 1 個の、3 桁の数字のインスタンス (オプションの市外局番) です。マッチする数字が取得されます。 |
| \)? | 0 個または 1 個の右カッコです。 |
| [\s.]* | 任意の空白文字またはピリオドが 0 個以上発生します。 |
| (\d{3}) | (電話交換局の) 3 桁の数字です。指定が必要で、取得されます。 |
| [\s.\-]* | 空白、ピリオドまたはハイフンの 0 個以上のインスタンスです。 |
| (\d{4}) | 電話番号の 4 桁の数字です。指定が必要で、取得されます。 |
| \s*$ | 0 個以上の空白文字があり、文字列の末尾が続きます。 |
置換テンプレートとは、リテラル文字、および正規表現で取得された部分文字列への参照を含むことができる
StringInterface です。リテラル文字は、そのまま置換の部分文字列に追加されます。正規表現で取得された部分文字列への参照は、正規表現の構文の参照と同じ形式です。つまり、最初に取得された文字列が \1、2 番目が \2 のように参照されます。9 個を超える参照がある場合は、参照番号をカッコに入れます。たとえば、 \(10) のようになります。
正規表現で取得された部分文字列がない場合、\1 を使用することによって正規表現とマッチした文字列全体を置換文字列に挿入できます。
| 例:
マッチした部分文字列の置換 |
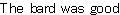 |
{import * from CURL.LANGUAGE.REGEXP}
{regexp-subst "foo", "The food was good", "bar"} | |
既定では、
regexp-subst は正規表現とマッチする最初の部分文字列だけを置換します。オプションの
replace-all? 引数を指定すると、マッチする部分文字列がすべて置換されます。
| 例:
部分文字列のすべてのインスタンスの置換 |
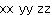 |
{import * from CURL.LANGUAGE.REGEXP}
{regexp-subst "dbl-(.)", "dbl-x dbl-y dbl-z", "\\1\\1",
replace-all?=true} | |
名前がつけられた部分文字列は、
部分文字列に名称を付ける のセクションで説明されているように、
(?P=name) シンタックスを使用して参照することができます。
| 例:
名前が付けられた部分文字列の置換 |
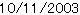 |
{import * from CURL.LANGUAGE.REGEXP}
{regexp-subst
|"(?P\d\d\d\d)-(?P\d\d)-(?P\d\d)"|,
"2003-10-11",
|"(?P=month)/(?P=day)/(?P=year)"|
}
| |
| 例:
明示的な Matcher の使用 |
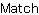 |
{import * from CURL.LANGUAGE.REGEXP}
{value
let my-string:String = "Curl is great, I like Curl"
let m:Matcher = {Matcher "^Curl.*Curl$"}
{if {regexp-match? m, my-string} then
{text Match}
else
{text No match}
}
}
| |
You can set
case-sensitive?,
multiline?,
and
single-line? without using a
Matcher
explicitly with the
i,
m, and
s flags in a
regular expression.
数値名か正規表現で割り当てられた名前のいずれかを使用した結果の部分文字列にアクセスすることができます。以下のサンプルは最初の括弧の組み合わせで捕捉された部分文字列を取得します。
| 例:
Using numeric name |
 |
{import * from CURL.LANGUAGE.REGEXP}
{value
let matcher:Matcher = {Matcher |"<(.*)>"|}
{if-non-null state = {matcher.match ""} then
state[1]
else
"NO-MATCH"
}
}
| |
このサンプルは、名前 match-name を部分文字列に割り当てています。
| 例:
Using assigned name |
 |
{import * from CURL.LANGUAGE.REGEXP}
{value
1 let matcher:Matcher = {Matcher |"<(?P.*)>"|}
{if-non-null state = {matcher.match ""} then
state["match-name"]
else
"NO-MATCH"
}
}
| |
| 例:
MatchState.substitute の使用 |
 |
{import * from CURL.LANGUAGE.REGEXP}
{value
let string:StringInterface = "one two three four"
let m:Matcher = {Matcher "(?Ptwo)"}
let s:StringBuf = {StringBuf}
let match-end:int = 0
{if-non-null state = {m.match string} then
let (match-start:int, match-length:int) = {state.get-range "match-name"}
|| マッチした範囲の前に全てを付加します。
{s.write-one-string
string, start = match-end, length = match-start - match-end
}
|| 置換を実行
{state.substitute "[(?P=match-name) or five]", buf = s}
set match-end = match-start + match-length
}
|| 最後のマッチ以下を追加します。
{s.write-one-string string, start = match-end}
s
}
| |
Copyright © 1998-2019 SCSK Corporation.
All rights reserved.
Curl, the Curl logo, Surge, and the Surge logo are trademarks of SCSK Corporation.
that are registered in the United States. Surge
Lab, the Surge Lab logo, and the Surge Lab Visual Layout Editor (VLE)
logo are trademarks of SCSK Corporation.