Curl® IDE には、Curl® 言語アプリケーションのパフォーマンスを解析するためのメカニズムが用意されています。Curl IDE のプロファイリング機能は、IDE のユーザー インターフェイスを使用するか、またはプロファイリング API の関数をソース コードに含めることによって使用できます。この機能は、Curl Pro/IDE でのみ利用できます。「
Curl 及び Curl Pro 製品」を参照してください。
| 要約: | Curl プロファイリングは次の 2 ステップのプロセスから成り立っています。 - 実行中のアプレットのパフォーマンス データの収集。
- プロファイル ビューアおよび IDE エディタでデータを分析。
|
Curl アプレットをプロファイルするには、まずパフォーマンス データを収集する必要があります。データ収集はアプレットのコンテキスト メニューから開始および停止できます。ブラウザ ウィンドウで実行されているアプレットをコントロール+右クリックしてコンテキスト メニューにアクセスし、[プロファイリングの開始/停止] を選択します。プロファイリングを停止すると、IDE によって自動的にプロファイル ビューアが起動され、収集したパフォーマンス データ セットが表示されます。特にプロファイリング時間が数秒以上であったためにサンプル セットが大きくなった場合は、ビューアが画面に表示されるまで時間がかかる可能性があります。
このデータ セットは、後で使用できるようにプロファイル ビューアの [ファイル] メニューにある [保存] コマンドで保存できます。保存されているデータ セットを [ファイル] メニューから開くこともできます。
データを収集するときに、Curl プロファイラはアプレットの情報サンプルを取得してそれをメモリに格納します。これらのデータ サンプルに基づいて、プロファイル ビューアに時間とパーセンテージの統計情報が表示されます。
プロファイリングの際に、アプレットをデバッグ可能またはデバッグ不可能の形式にするかどうかも考慮するべきです。
デバッグ可能なアプレットは、パフォーマンスデータとソースコード内の行番号をプロファイラがリンクするための追加情報を含んでいます。
この情報は、
プロファイラ ソース ビュー
を実行するために使用されます。ただし、この追加情報によるオーバーヘッドによって、
アプレットの実行により時間がかかることになり、不正確なパフォーマンス情報が導入される可能性もあります。
初回のプロファイリングはデバッグ可能なアプレットで実行するのが便利な方法です。
デバッグ可能なアプレットを使用することで、プロファイラの全機能を駆使して、
最も深刻なパフォーマンスの問題を識別することができます。
後に、アプレットをデバッグ不可能な形式に変換して、パフォーマンスを再分析し、
パフォーマンスを調整するためのより正確な結果を得ることもできます。
| 要約: | - パフォーマンス データを分析するには、プロファイル ビューアを使用します。
- ビューア ウィンドウには、相互関係のある情報が表示されるいくつかのペインがあります。これらのペインは、作業スタイルに合わせて構成できます。
- プロファイル ビューアから簡単に IDE ソース エディタにアクセスできます。
|
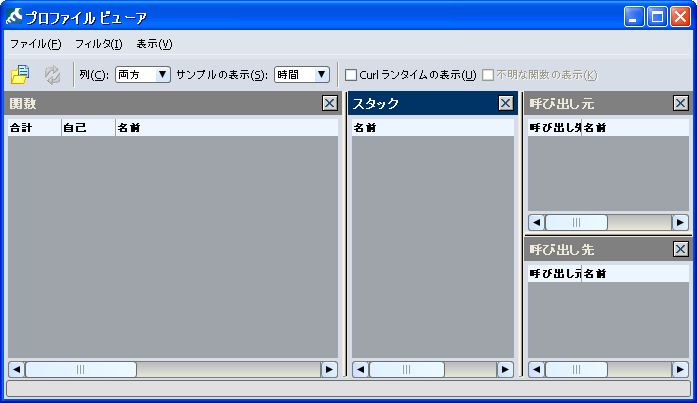
プロファイル ビューアは、Curl プロファイラによって収集されたパフォーマンス データが表示されるウィンドウです。IDE エディタの [ツール] メニューからこのビューアを起動できます。プロファイル ビューア ウィンドウには 4 つのペインがあり、それぞれにデータのリストが含まれます。ビューアにはメニューとツール バーもあります。次の各セクションでは、プロファイル ビューア UI のこれらのコンポーネントについて説明します。
プロファイル ビューア ウィンドウのペインは、IDE のペインと同じように非表示にしたり、位置やサイズを変更したりできます。詳細については、「
ウィンドウ構成の変更」を参照してください。
次の図は、既定のレイアウトを示しています。このレイアウトは、[表示] メニューの [既定に戻す] コマンドで復元できます。
このペインには、データ サンプリング中にプロファイルされた関数のリストが表示されます。このリストには次の列が含まれます。
- [合計] 列には、この関数およびこの関数から呼び出された関数に費やされた時間の合計が表示されます。
- [自己] 列には、この関数に費やされた時間が表示され、この関数から呼び出された関数に費やされた時間は含まれません。
- [名前] 列には、この関数の名前が表示されます。
- [パッケージ] 列には、この関数を含むパッケージの名前が表示されます。
- [ファイル] 列には、この関数を含むファイルの名前が表示されます。
既定では、このペイン内のアイテムは [自己] 列の時間順にソートされます。
ツールバーの
[列:]、
[サンプルの表示:]、
[Curl ランタイムの表示:] 及び
[未知の関数の表示:] は、このペインのデータの表示を制御します。
フィルタ メニューの
[パッケージごとに色付け]アイテムは、情報がパッケージ毎に色づけされるかどうかを制御します。
プロファイル ビューワ ツール バー と
フィルタ メニュー を参照してください。
[関数] ペインで関数をクリックすると、他のペインが更新され、それらのペインに選択した関数に関する詳細情報が表示されます。このリストの関数をダブルクリックすると、IDE ソース エディタにその関数を含むファイルが開き、プロファイリング情報も表示されます。詳細については、「
プロファイラ ソース ビュー」を参照してください。
[スタック] ペインには、この関数までの呼び出しチェインの中で、費やされた時間が最も長いチェインが表示されます。関数は、複数の関数から呼び出される場合もあれば、他の複数の関数を呼び出す場合もあります。したがって、このペインでは、おおよそのプログラム動作のみ確認できます。また、アプリケーションが何に時間を費やしているのかを迅速に把握できます。このリストの関数をダブルクリックすると、[関数] ペインでその関数が選択されます。
[関数] ペインで関数を選択すると、その関数を呼び出したすべての関数のリストが [呼び出し元] ペインに表示されます。このリストは、[呼び出し先の %] 列の降順にソートされます。[呼び出し先の %] 列には、選択された関数の合計実行時間のうち、[名前] 列の関数によって呼び出された場合の実行時間の占める割合が表示されます。このパーセンテージは、単純に [名前] 列内の関数が選択された関数を呼び出した頻度を示すものではありません。たとえば、ある関数が長い処理時間を要する大きいデータ構造を引数に指定して別の関数を呼び出した場合に、[呼び出し先の %] 列の値が高くなる可能性があります。
[呼び出し元] ペインで関数をダブルクリックすると、その関数は[関数] ペインで選択された状態になり、[呼び出し元] ペインの表示が新しく選択された関数を呼び出した関数のリストに変わります。
[呼び出し先] ペインには、[関数] ペインで選択された関数から呼び出された関数のリストが表示されます。このリストの関数をダブルクリックすると、[関数] ペインでその関数が選択されます。
[呼び出し元の %] 列には、選択された関数のサンプルのうち、リスト内の各関数を呼び出した場合のサンプルの割合が表示されます。アイテム <self time> は、その関数自体に費やされた時間を示します。
- [開く] は、プロファイル データ ファイルを開きます。プロファイル データ ファイルは、プロファイル ビューアでデータ セットに対して [名前を付けて保存] を実行するか、またはパフォーマンス API を使用することによって作成できます。詳細については、「パフォーマンス API」 を参照してください。
- [閉じる] は、現在開いているデータ セットを閉じます。
- [名前を付けて保存] は、現在開いているデータ セットを、[開く] で開くことができるプロファイル データ ファイルとして保存します。
- [再ロード] は、プロファイル データ ファイルを再ロードします。これはファイルを繰り返し生成する場合に役立ちます。再ロードではフィルタ設定が保持されますが、ファイルを閉じて再度開くと保持されません。
- [終了] は、プロファイル ビューアを閉じます。
[フィルタ] メニューを使用すると、収集したデータの一部を表示から除外できます。これにより、残りのデータの表示を見やすくすることができます。
フィルタには、2 つのアクション レベルがあります。1 つは、選択された関数に対してのみ機能するアクションです。もう 1 つは、関数を含むパッケージ全体に対して機能するアクションです。
- ["関数" のソースの表示] は、IDE エディタにその関数を含むファイルを開き、プロファイリング情報も表示します。これは、[関数] ペインで関数をダブルクリックしたときと同じ結果です。
- 除外
[除外] フィルタは、選択されたデータを表示と統計の計算から完全に除外します。詳細については、「
除外」を参照してください。
- フォーカス
[フォーカス] フィルタは、選択されたデータ以外のすべてを表示から除外します。詳細については、「
フォーカス」を参照してください。
- 非表示
[非表示] フィルタは、選択されたデータを非表示にして、非表示の関数に費やされた時間を呼び出し関数の属性にします。詳細については、「
非表示」を参照してください。
- [フィルタのリセット] は、データ フィルタを既定の状態に戻します。
- [Curl ランタイムの表示] は、Curl ランタイムに含まれる関数についてサンプルされたデータを表示するかどうかを制御します。Curl ランタイムの関数のパフォーマンスは変更できないため、既定では、ビューアにこの情報は表示されません。Curl ランタイムの呼び出しを表示する場合は、このチェックボックスをオンにします。たとえば、コードで特定のランタイム関数が呼び出される頻度を調べる場合などです。
- [パッケージごとに色付け] は、関数データを色付きで表示します。色は、関数が定義されているパッケージを示します。
- [アクティブなペインを隠す] は現在アクティブなペインを非表示にします。ペインに表示されている情報は変わりません。このメニュー項目を選択すると、ペインのタイトル バーの右側にある [閉じる] アイコンをクリックした場合と同じ結果になります。
- 次の各メニュー項目を選択すると、対応するプロファイル ビューア ペインがアクティブになり、非表示のペインは表示されます。メニュー項目の左側に小さな点がある場合、そのペインが現在表示されていることを意味します。詳細については、「プロファイル ビューアのペイン」を参照してください。
- 既定に戻す このメニュー項目を選択すると、既定のプロファイル ビューア レイアウトに戻ります。
| 機能 | 説明 |
|---|
|
| [ファイル] メニューの [開く] と同じです。 |
|
| ファイルを再ロードします。 |
|
| [関数] ペインに [自己]、[合計]、または [両方] を表示します。 |
|
| パフォーマンス データを合計サンプル時間に対する割合、秒数、または取得されたサンプル数 で表示します。 |
|
| Curl ランタイムの関数を表示します。 |
|
| Curl ランタイムの不明な関数を表示します。 |
| 要約: | デバッグ可能なアプレットをプロファイルする際に、IDE ソース エディタ内でプロファイリング データを表示できます。 |
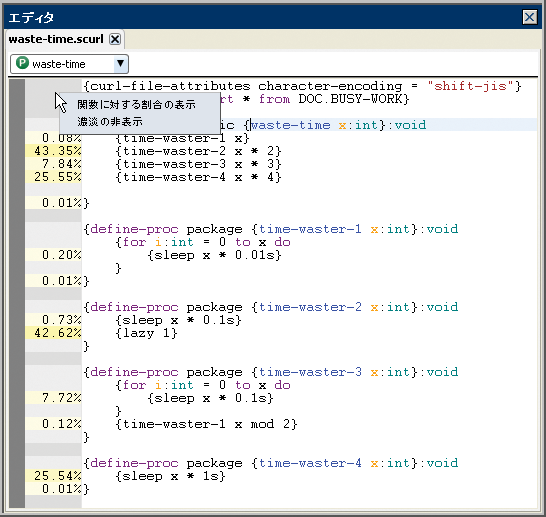
IDE では、プロファイル ビューアだけでなく IDE ソース エディタでもプロファイリング データを直接表示できます。プロファイル データ ファイルを開くと、現在のプロファイル データ セット内のファイルのプロファイリング データが表示されます。プロファイリング データは、ブレークポイント パネルとソース コードの間の追加列に表示されます。
行番号のデータは、デバッグ可能なアプレットをプロファイルする場合のみに利用できます。
デバッグ不可能なアプレットは、パフォーマンスとソースコード内の行番号を連結する情報を提供していません。
この列には 2 つの項目が表示されます。各行について、その行がサンプル対象の関数の内部にあるかどうかが示されます。トップレベルのフォームのコンパイル方法により、この情報はプロシージャまたはメソッドの場合のみ正確です。また、現在のサンプル セットに基づいて、各サンプル対象行にかかった時間も表示されます。各サンプル対象行のデータ表示の背景には、費やされた時間の長さに従って濃淡が付けられます。最も時間のかかった行は濃い黄色、最も時間のかからなかった行は明るい黄色になります。濃淡の設定はオプション機能であり、コンテキスト メニューで無効にできます。
プロファイリング データは、サンプル セットの合計時間に対する割合または現在の関数に対する割合で表示できます。
列を右クリックすると、次のコンテキスト メニューが表示されます。
- [合計に対する割合の表示] または [関数に対する割合の表示] は、データの表示に関する 2 つのオプションを切り替えます。
- [濃淡の表示] または [濃淡の非表示] は、データの濃淡付け機能をオンまたはオフにします。
次の図は、ソース エディタ ペインを示しています。プロファイリング データが現在の関数に対する割合で表示され、コンテキスト メニューが表示されています。背景に濃淡を付けると、最も時間を消費する行を識別できます。
| 要約: | - プロファイリング データは、ソース コードに関数呼び出しを追加することによって収集できます。
- データは指定したファイルに格納されます。
|
どのコード領域を詳しく調べるか明確にわかっている場合は、パフォーマンス API の呼び出しをコードに追加できます。これらの関数は、アプレットが実行されるたびに自動的にパフォーマンス データを記録します。API はパッケージ
CURL.IDE.PERFORMANCE にあり、次のプロシージャを含んでいます。
- initialize-performance-profiling
サンプリング パフォーマンス プロファイラを初期化するには、このプロシージャを使用します。このプロシージャのパラメータは
output-file と
sampling-interval です。
output-file パラメータには、プロファイリング データを格納するローカルの
Url を指定します。既存のファイルは上書きされます。ファイル拡張子は「.cprof」です。拡張子を指定しなかった場合は、自動的に付加されます。
sampling-interval パラメータは 1 秒間に取得するサンプル数です。これはプロファイラに対する要求であり、プロファイリング レートを保証するものではありません。実際のプロファイリング レートは、出力ファイルに記録されます。
- start-performance-profiling および stop-performance-profiling
プロファイラによるサンプルの収集を開始および停止するには、これらの 2 つのプロシージャを使用します。これらの呼び出しは、
StopWatch と同じように使用できます。開始と停止が何度でも可能で、サンプルは 1 つのサンプル セットに蓄積されます。
- finish-performance-profiling
このプロシージャは、サンプルの収集が終了した後で呼び出す必要があります。収集したデータを initialize-performance-profiling で指定されたファイルに書き込みます。数分間のサンプリングの結果生成されたサンプル セットのように、大きいサンプル セットの場合は、このデータの書き込みに数秒かかることがあります。
- cancel-performance-profiling
プロファイラは初期化されたので、このプロシージャを使用してプロファイラをキャンセルし、収集したサンプルを破棄します。
ブラウザのコンテキスト メニューまたはパフォーマンス API の呼び出しによってパフォーマンス データを収集したら、そのデータを IDE プロファイル ビューアで表示します。ビューアの機能を使用して、収集されたデータを調べたりコードのパフォーマンスを詳細に把握したりできます。
このセクションでは、小さいサンプル アプレットを使用して、IDE プロファイル ビューアでパフォーマンスを分析する方法を示します。すべてのスクリーン ショットはこの例に基づいています。この例は、
d:\automated-build-temp\build\win32-atom\docs\default\examples\uguide\profiler.zip に含まれています。このアーカイブから適切なディレクトリにファイルを解凍してから、IDE で開いて実行します。「
内容の充実したサンプル ファイル」を参照してください。
プロファイル ビューアには、選択した関数に費やされた時間が表示されます。IDE はこのような時間に基づくリソース コストを計算するときに、自己時間と合計時間の両方を計算します。合計時間は、その関数とその関数から呼び出された関数に費やされた時間です。自己時間は、その関数だけに費やされた時間です。ほとんどの場合、最適化できないすべての関数をビューから削除したら、自己時間が考慮すべき最も重要な値になります。
注意: アプリケーションが関数を再帰的に呼び出す場合、関数 ペインの 合計 列はスタック上の関数のすべてのインスタンスの合計をレポートします。これは実際のパフォーマンスを反映しない数字をもたらす可能性があります。再帰的に呼び出される関数をプロファイルする必要がある場合は、戦略的に配置されたパフォーマンス API への呼び出しがもっとも有用な情報を提供するでしょう。
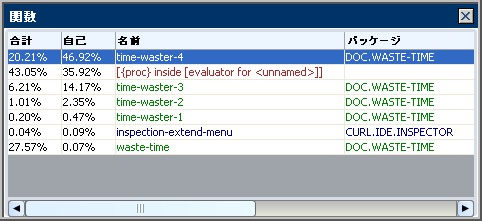
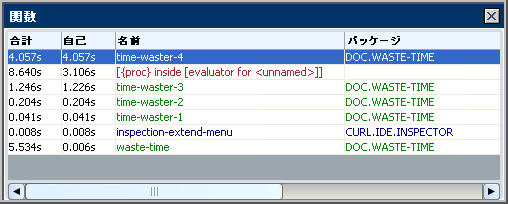
ビューアのツール バーにある列コントロールで合計時間、自己時間、または両方を選択できます。次の図は、[合計]時間と [自己] 時間の両方が表示された [関数] ペインを示しています。
フィルタリング機能を使用すると、全体のパフォーマンス サンプルのサブセットをプロファイル ビューアで表示できます。パフォーマンス データ サンプルには、自分のパフォーマンス問題に関連しない情報も含まれている場合があります。[除外]、[フォーカス]、および[非表示] フィルタを使用すると、サンプル内の最も関連性のあるデータを選択できます。これらのすべてのフィルタでは、選択された関数または選択された関数を含むパッケージ全体をフィルタできます。
フィルタを適用するには、[フィルタ] メニュー、またはプロファイル ビューア ウィンドウのどこでも使用できる右クリックのコンテキスト メニューを使用します。
[非表示] フィルタは、指定されたサンプルをレポートから削除し、非表示の関数に費やされた時間をその関数を呼び出した関数の属性にします。このフィルタは、パッケージの構造を無視してそのオーバーヘッドを記録する場合に役立つ方法です。
また、Curl ランタイムの関数を非表示にしたり表示したりすることもできます。Curl ランタイムの操作にかかる時間については、短縮できないので、考慮する必要はありません。ただし、コードにある程度のオーバーヘッドがかかることに注意してください。既定では、プロファイル ビューアは Curl ランタイムの関数を非表示にします。
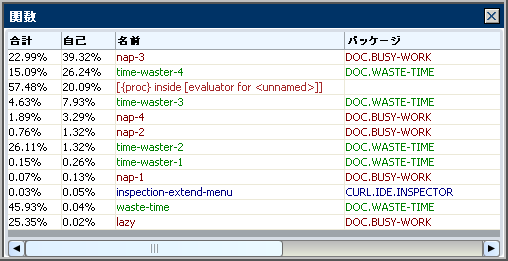
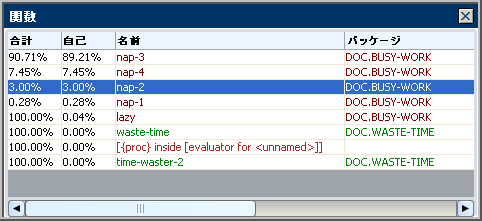
次の図は、BUSY-WORK パッケージを非表示にするようにフィルタされたサンプル データを示しています。time-waster-2 の時間の値が増えていることに注意してください。time-waster-2 関数は、BUSY-WORK パッケージの lazy を呼び出します。呼び出された関数は、BUSY-WORK パッケージの他のすべての関数を呼び出します。したがって、BUSY-WORK を非表示にすると、BUSY-WORK 内の関数に費やされたすべての時間が time-waster-2 の属性になります。
[除外] フィルタは、サンプル データを、表示とパフォーマンス統計情報を生成する計算から除外します。このフィルタは、一部のコードのオーバーヘッドを無視する場合に役立ちます。たとえば、後で改良する予定があるルーチンまたはそれ以上改良できないルーチンを無視することが必要になる場合があります。そのような関数をプロファイル ビューアの表示から除外すると、それらの関数にかかる時間を考慮する必要がなくなります。
次の図は、BUSY-WORK パッケージを除外するようにフィルタされたサンプル データを示しています。残りの関数の時間がフィルタされる前のデータから変わっていないことに注意してください。データをサンプル セットから削除したたため、パーセンテージの値が変わります。
[フォーカス] フィルタは、[除外] フィルタの反対です。[フォーカス] フィルタは、現在選択されているサンプル以外のすべてのサンプルを削除します。フォーカスされた関数の上のスタック フレームも無視されます。
[フォーカス] フィルタを使用すると、大きいサンプルの特定部分にすばやく表示を絞り込むことができます。
次の図は、BUSY-WORK パッケージにフォーカスが設定されたサンプル データ セットを示しています。
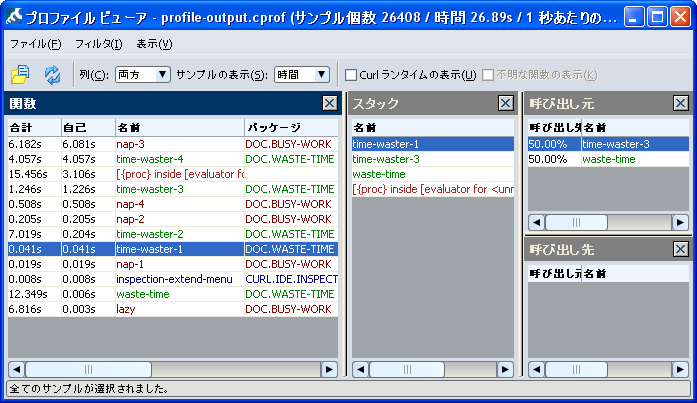
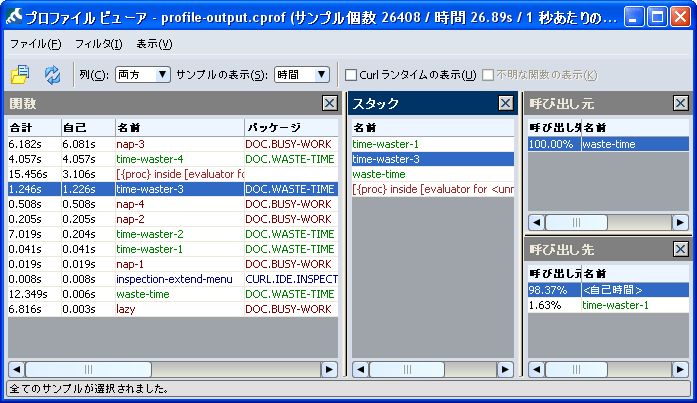
4 つのプロファイル ビューア ペインには、関連するデータ セットが表示されます。[関数] ペインで関数を選択すると、その関数に関連する情報が他の 3 つのペインに表示されます。次の図では、time-waster-1 関数が選択されています。[スタック] ペインには、time-waster-1 までの最もコストのかかるパスが表示されます。他の 2 つのペインでは、その関数が time-waster-3 と waste-time から呼び出され、その関数自体は他の関数を呼び出さないことが示されます。
この情報に基づいて、time-waster-3 をさらに詳しく調べることが必要になる場合もあります。この単純な例では、[関数] ペインで簡単にこの関数を見つけられます。データ サンプルが大きく複雑な場合は、呼び出し関数が見つかりにくくなる可能性があります。他のペインに表示されている関数名をダブルクリックして、その関数を [関数] ペインで選択したり、他のペインの表示を調整したりできます。
次の例は、time-waster-3 をダブルクリックした後のプロファイル ビューアを示しています。
[関数] ペイン内の関数を関数名、パッケージ、またはファイル名でソートすると、特定の関数が見つかりやすくなります。列の見出しをクリックして、その列の値でペイン内のデータをソートできます。
Copyright © 1998-2019 SCSK Corporation.
All rights reserved.
Curl, the Curl logo, Surge, and the Surge logo are trademarks of SCSK Corporation.
that are registered in the United States. Surge
Lab, the Surge Lab logo, and the Surge Lab Visual Layout Editor (VLE)
logo are trademarks of SCSK Corporation.